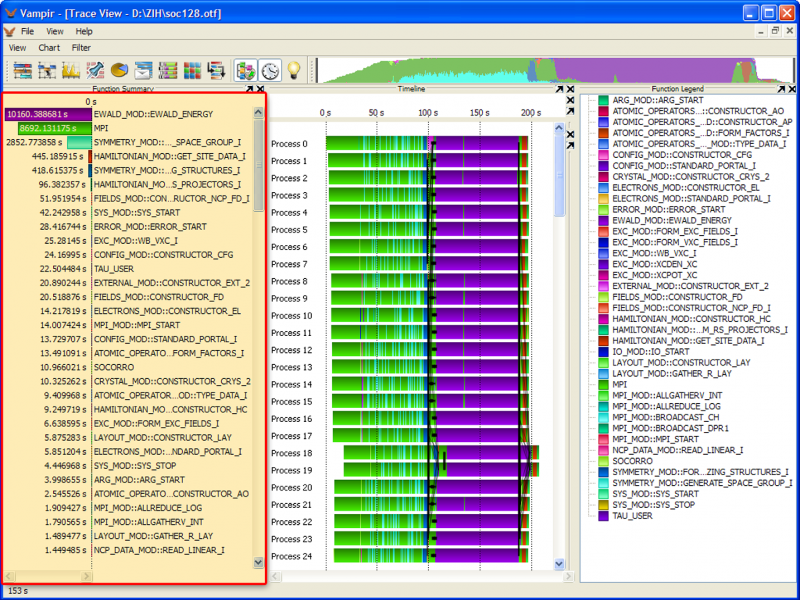
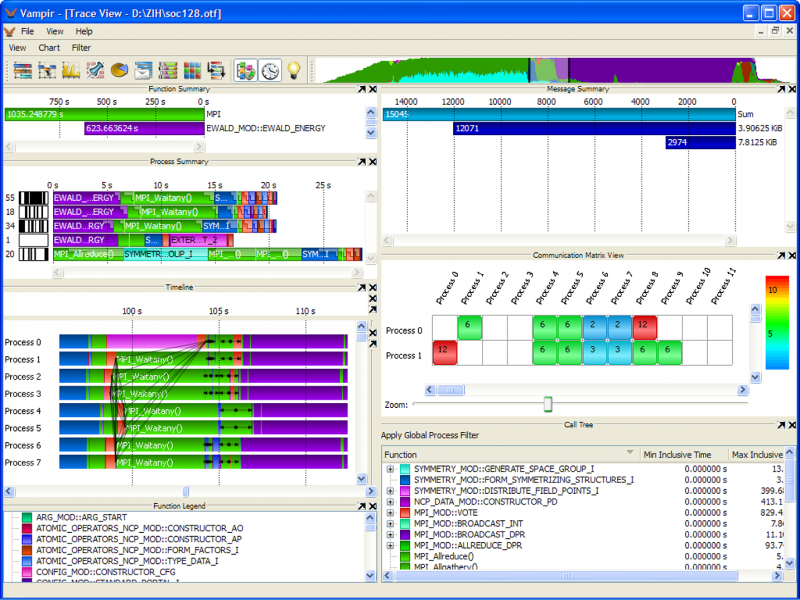
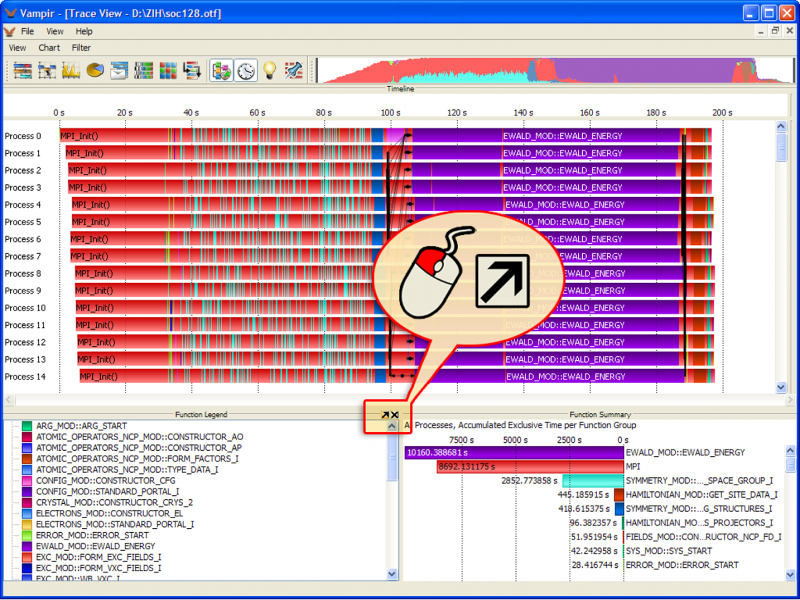
VampirTrace consists of a tool set and a runtime library for
instrumentation and tracing of software applications. It is particularly
tailored to parallel and distributed High Performance Computing (HPC)
applications.
VampirTrace is currently available on FutureGrid machines under module
‘vampirtrace’. VampirTrace is also available in OpenMPI versions 1.5.x
or higher. For example on Bravo, it is available as openmpi/1.5.4-gnu
or openmpi/1.5.4-intel.
The instrumentation part of VampirTrace modifies a given application in
order to inject additional measurement calls during runtime. The tracing
part provides the actual measurement functionality used by the
instrumentation calls. By this means, a variety of detailed performance
properties can be collected and recorded during runtime. This includes
function enter and leave events, MPI communication, OpenMP events, and
performance counters.
After a successful tracing run, VampirTrace writes all collected data to
a trace file in the Open Trace Format (OTF). As a result, the
information is available for post-mortem analysis and visualization by
various tools. Most notably, VampirTrace provides the input data for the
Vampir analysis and visualization tool.
Trace files can quickly become very large, especially with automatic
instrumentation. Tracing applications for only a few seconds can result
in trace files of several hundred megabytes. To protect users from
creating trace files of several gigabytes, the default behavior of
VampirTrace limits the internal buffer to 32MB per process (2GB on
FutureGrid systems). Thus, even for larger scale runs the total trace
file size will be moderate.
The following list shows a summary of all instrumentation and tracing
features that VampirTrace offers. Note that not all features are
supported on all platforms.
Tracing of User Functions
- Record function enter and leave events
- Record name and source code location (file name, line)
- Manual instrumentation using VampirTrace API
MPI Tracing
- Record MPI functions
- Record MPI communication: participating processes, transferred bytes,
tag, communicator
OpenMP Tracing
- OpenMP directives, synchronization, thread idle time
- Also hybrid (MPI and OpenMP) applications are supported
Pthread Tracing
- Trace POSIX thread API calls
- Also hybrid (MPI and POSIX threads) applications are supported
Java Tracing
- Record method calls
- Using JVMTI as interface between VampirTrace and Java Applications
3rd-Party Library tracing
- Trace calls to arbitrary third party libraries
- Generate wrapper for library functions based on library’s header
file(s)
- No recompilation of application or library is required
MPI Correctness Checking
- Record MPI usage errors
- Using UniMCI as interface between VampirTrace and a MPI correctness
checking tool (e.g., Marmot)
User API
- Manual instrumentation of source code regions
- Measurement controls
- User-defined counters
- User-defined marker
Performance Counters
- Hardware performance counters using PAPI, CPC, or NEC SX performance
counter
- Resource usage counters using getrusage
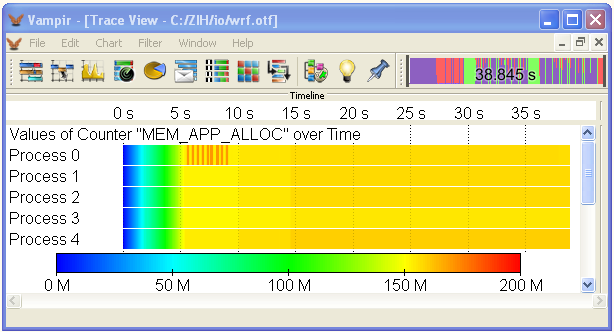
Memory Tracing
- Trace GLIBC memory allocation and free functions
- Record size of currently allocated memory as counter
I/O Tracing
- Trace LIBC I/O calls
- Record I/O events: file name, transferred bytes
CPU ID Tracing
- Trace core ID of a CPU on which the calling thread is running
- Record core ID as counter
Fork/System/Exec Tracing
- Trace applications calling LIBC’s fork, system, or one of the exec
functions
- Add forked processes to the trace
Filtering & Grouping
- Runtime and post-mortem filter (i.e., exclude functions from being
recorded in the trace)
- Runtime grouping (i.e., assign functions to groups for improved
analysis)
OTF Output
- Writes compressed OTF files
- Output as trace file, statistical summary (profile), or both
Instrumentation
To perform measurements with VampirTrace, the user’s application program
needs to be instrumented; that is, at specific points of interest
(called “events”), VampirTrace measurement calls have to be activated.
Common events are, among others, entering and leaving of functions as
well as sending and receiving of MPI messages. VampirTrace handles this
automatically by default. In order to enable the instrumentation of
function calls, the user needs only to replace the compiler and linker
commands with VampirTrace’s wrappers (see below). VampirTrace supports
different ways of instrumentation as described in the sections below.
Compiler Wrappers
All the necessary instrumentation of user functions, MPI, and OpenMP
events is handled by VampirTrace’s compiler wrappers (vtcc, vtcxx,
vtf77, and vtf90). In the script used to build the application (e.g., a
makefile), all compile and link commands should be replaced by the
VampirTrace compiler wrapper. The wrappers perform the necessary
instrumentation of the program and link the suitable VampirTrace
library. The following list shows some examples specific to the
parallelization type of the program:
Compiling serial codes is the default behavior of the wrappers. Simply
replace the compiler by VampirTrace’s wrapper:
original: gfortran hello.f90 -o hello
with instrumentation: **vtf90** hello.f90 -o hello
This will instrument user functions (if supported by the compiler) and
link the VampirTrace library.
MPI instrumentation is always handled by means of the PMPI interface,
which is part of the MPI standard. This requires the compiler wrapper to
link with an MPI-aware version of the VampirTrace library. If your MPI
implementation uses special MPI compilers (e.g. mpicc, mpxlf90), you
will need to tell VampirTrace’s wrapper to use this compiler instead of
the serial one:
original: mpicc hello.c -o hello
with instrumentation: **vtcc -vt:cc mpicc** hello.c -o hello
MPI implementations without their own compilers require the user to link
the MPI library manually. In this case, simply replace the compiler by
VampirTrace’s compiler wrapper:
original: icc hello.c -o hello –lmpi
with instrumentation: **vtcc** hello.c -o hello -lmpi
If you want to instrument MPI events only (this creates smaller trace
files and less overhead), use the option -vt:inst manual to disable
automatic instrumentation of user functions.
- Threaded parallel programs
When VampirTrace detects OpenMP or Pthread flags on the command line,
special instrumentation calls are invoked. For OpenMP events, OPARI is
invoked for automatic source code instrumentation.
original: ifort <-openmp\|-pthread> hello.f90 -o hello
with instrumentation: **vtf90** <-openmp\|-pthread> hello.f90 -o hello
For more information about OPARI, read the documentation available in
VampirTrace’s installation directory at:
share/vampirtrace/doc/opari/Readme.html
- Hybrid MPI/Threaded parallel programs
With a combination of the above mentioned approaches, hybrid
applications can be instrumented:
original: mpif90 <-openmp\|-pthread> hello.F90 -o hello
with instrumentation: **vtf90 -vt:f90 mpif90** <-openmp\|-pthread> hello.F90 -o hello
The VampirTrace compiler wrappers automatically try to detect which
parallelization method is used by means of the compiler flags (e.g.,
-lmpi, -openmp or -pthread) and the compiler command (e.g. mpif90). If
the compiler wrapper failed to detect this correctly, the
instrumentation could be incomplete and an unsuitable VampirTrace
library would be linked to the binary. In this case, you should tell the
compiler wrapper which parallelization method your program uses by using
the switches -vt:mpi, -vt:mt, and -vt:hyb for MPI, multithreaded, and
hybrid programs, respectively. Note that these switches do not change
the underlying compiler or compiler flags. Use the option -vt:verbose to
see the command line that the compiler wrapper executes.
The default settings of the compiler wrappers can be modified in the
files share/vampirtrace/vtcc-wrapper-data.txt (and similar for the
other languages) in the installation directory of VampirTrace. The
settings include compilers, compiler flags, libraries, and
instrumentation types. You could, for instance, modify the default C
compiler from gcc to mpicc by changing the line compiler=gcc to
compiler=mpicc. This may be convenient if you instrument MPI parallel
programs only.
Instrumentation Types
The wrapper option -vt:inst <insttype> specifies the instrumentation
type to be used. The following values for <insttype> are possible:
Fully-automatic instrumentation by the compiler
Manual instrumentation by using VampirTrace’s API (needs source-code
modifications)
Automatic Instrumentation
Automatic instrumentation is the most convenient method to instrument
your program. If available, simply use the compiler wrappers without any
parameters, e.g.:
Notes for Using the GNU or Intel Compiler
For these compilers, the command nm is required to get symbol
information of the running application executable. To get the
application executable for nm during runtime, VampirTrace uses the /proc
file system. As /proc is not present on all operating systems, automatic
symbol information might not be available. In this case, it is necessary
to set the environment variable VT APPPATH to the pathname of the
application executable to get symbols resolved via nm.
Should any problems emerge to get symbol information automatically, then
the environment variable VT GNU NMFILE can be set to a symbol list file,
which is created with the command nm, like:
To get the source code line for the application functions use nm -l (on
Linux systems). VampirTrace will include this information in the trace.
Note that the output format of nm must be written in BSD-style. See the
manual page of nm for help in dealing with the output format setting.
Notes on Instrumentation of Inline Functions
Compilers behave differently when they automatically instrument inlined
functions. The GNU and Intel (10.0++) compilers instrument all functions
by default when they are used with VampirTrace. They therefore switch
off inlining completely, disregarding the optimization level chosen. One
can prevent these particular functions from being instrumented by
appending the following attribute to function declarations, hence making
them able to be inlined (this works only for C/C++):
\_\_attribute\_\_ ((\_\_no\_instrument\_function\_\_))
The PGI and IBM compilers prefer inlining over instrumentation when
compiling with enabled inlining. Thus, one needs to disable inlining to
enable the instrumentation of inline functions and vice versa.
The bottom line is that a function cannot be inlined and instrumented at
the same time. Note that you can also use the option -vt:inst manual
with non-instrumented sources. Binaries created in this manner only
contain MPI and OpenMP instrumentation, which might be desirable in some
cases. For more on how to inline functions, read your compiler’s manual.
Using the VampirTrace API
The VT USER START, VT USER END calls can be used to instrument any
user-defined sequence of statements.
Fortran
#include "vt\_user.inc"
VT\_USER\_START(’name’)
...
VT\_USER\_END(’name’)
C
#include "vt\_user.h"
VT\_USER\_START("name");
...
VT\_USER\_END("name");
If a block has several exit points (as is often the case for functions),
all exit points have to be instrumented with VT USER END, too.
For C++ it is simpler, as is demonstrated in the following example. Only
entry points into a scope need to be marked. The exit points are
detected automatically when C++ deletes scope-local variables.
C++
#include "vt\_user.h"
{
VT\_TRACER("name");
...
}
The instrumented sources have to be compiled with -DVTRACE for all three
languages; otherwise the VT * calls are ignored. Note that Fortran
source files instrumented this way have to be preprocessed, too.
In addition, you can combine this particular instrumentation type with
all other types. In such a way, all user functions can be instrumented
by a compiler while special source code regions (e.g., loops) can be
instrumented by VT’s API.
Use VT’s compiler wrapper (described above) for compiling and linking
the instrumented source code, such as:
- combined with automatic compiler instrumentation:
vtcc **-DVTRACE** hello.c -o hello
- without compiler instrumentation:
vtcc -vt:inst manual **-DVTRACE** hello.c -o hello
Note that you can also use the option -vt:inst manual with
non-instrumented sources. Binaries created in this manner only contain
MPI and OpenMP instrumentation, which might be desirable in some cases.
Measurement Controls
Switching Tracing On/Off: In addition to instrumenting arbitrary
blocks of code, one can use the VT_ON/ VT_OFF instrumentation calls to
start and stop the recording of events. These constructs can be used to
stop recording of events for a part of the application and later resume
recording. For example, one could not collect trace events during the
initialization phase of an application and turn on tracing for the
computation part.
Furthermore, the “on/off” functionality can be used to control the
tracing behavior of VampirTrace, and allows you to trace only parts of
interests. Essentially, then, the amount of trace data can be reduced.
To check whether if tracing is enabled or not, use the call VT_IS_ON.
Please note that stopping and starting the recording of events has to be
performed at the same call stack level. If this is not the case, an
error message will be printed during runtime, and VampirTrace will abort
execution.
Intermediate Buffer Flush: In addition to an automated buffer flush
when the buffer is filled, it is possible to flush the buffer at any
point of the application. This way you can guarantee that after a manual
buffer flush there will be a sequence of the program with no automatic
buffer flush interrupting. To flush the buffer, you can use the call
VT_BUFFER_FLUSH.
Intermediate Time Synchronisation: VampirTrace provides several
mechanisms for timer synchronization. In addition, it is also possible
to initiate a timer synchronization at any point of the application by
calling VT_TIMESYNC. Please note that the user has to ensure that all
processes are actual at a synchronized point in the program (e.g., at a
barrier). To use this call, make sure that the enhanced timer
synchronization is activated (set the environment variable
VT_ETIMESYNC).
Intermediate Counter Update: VampirTrace provides the functionality
to collect the values of arbitrary hardware counters. Chosen counter
values are automatically recorded whenever an event occurs. Sometimes
(e.g., within a long-lasting function) it is desirable to get the
counter values at an arbitrary point within the program. To record the
counter values at any given point, you can call VT_UPDATE_COUNTER.
Note: For all three languages the instrumented sources have to be
compiled with -DVTRACE. Otherwise the VT * calls are ignored. In
addition, if the sources contain further VampirTrace API calls and only
the calls for measurement controls will be disabled, then the sources
must also be compiled with -DVTRACE_NO_CONTROL.
Tracing Calls to 3rd-Party Libraries
VampirTrace is also capable of tracing calls to third-party libraries
which come with at least one C header file, even without the library’s
source code. If VampirTrace was built with support for library tracing,
the tool vtlibwrapgen can be used to generate a wrapper library to
intercept each call to the actual library functions. This wrapper
library can be linked to the application, or used in combination with
the LD PRELOAD mechanism provided by Linux. The generation of a wrapper
library is done using the vtlibwrapgen command and consists of two
steps. The first step generates a C source file, providing the wrapped
functions of the library header file:
vtlibwrapgen -g SDL -o SDLwrap.c /usr/include/SDL/\*.h
This generates the source file SDLwrap.c that contains
wrapper-functions for all library functions found in the header-files
located in /usr/include/SDL/, and instructs VampirTrace to assign
these functions to the new group SDL. The generated wrapper source file
can be edited in order to add manual instrumentation or alter attributes
of the library wrapper. A detailed description can be found in the
generated source file or in the header file vt libwrap.h , which can
be found in the include directory of VampirTrace. To adapt the library
instrumentation it is possible to pass a filter file to the generation
process. The rules are like these for normal VampirTrace
instrumentation, where only 0 (exclude functions) and -1 (generally
include functions) are allowed.
The second step is to compile the generated source file:
vtlibwrapgen --build --shared -o libSDLwrap SDLwrap.c
This builds the shared library libSDLwrap.so, which can be linked to
the application or preloaded by using the environment variable LD
PRELOAD:
LD\_PRELOAD=$PWD/libSDLwrap.so <executable>
Runtime Measurement
Running a VampirTrace instrumented application should normally result in
an OTF trace file in the current working directory where the application
was executed. If a problem occurs, set the environment variable
VT_VERBOSE to 2 before executing the instrumented application in order
to see control messages of the VampirTrace runtime system which might
help tracking down the problem.
The internal buffer of VampirTrace is limited to 32 MB per process. Use
the environment variables VT_BUFFER_SIZE and VT_MAX_FLUSHES to
increase this limit.
Trace File Name and Location
The default name of the trace file depends on the operating system where
the application is run. On Linux, MacOS and Sun Solaris, the trace file
will be named like the application, e.g., hello.otffor the
executable hello. For other systems, the default name is a.otf.
Optionally, the trace file name can be defined manually by setting the
environment variable VT_FILE_PREFIX to the desired name. The suffix
.otf will be added automatically.
To prevent overwriting of trace files by repetitive program runs, one
can enable unique trace file naming by setting VT_FILE_UNIQUE to yes.
In this case, VampirTrace adds a unique number to the file names as soon
as a second trace file with the same name is created. A *.lock file is
used to count up the number of trace files in a directory. Be aware that
VampirTrace potentially overwrites an existing trace file if you delete
this lock file. The default value of VT_FILE_UNIQUE is no. You can
also set this variable to a number greater than zero, which will be
added to the trace file name. This way you can manually control the
unique file naming.
The default location of the final trace file is the working directory at
application start time. If the trace file will be stored in another
place, use VT_PFORM_GDIR to change the location of the trace file.
Environment Variables
Environment variables can be used to control nearly every aspect of the
measurement of a VampirTrace instrumented executable. (ToDo: link to
CheatSheet and Doku-PDF)
- records are stored, before being written to a file.
- VT_CLEAN
- Remove temporary trace files?
- yes
- VT_COMPRESSION
- Write compressed trace files?
- yes
- VT_FILE_PREFIX
- Prefix used for trace filenames.
-
- VT_FILE_UNIQUE
- Enable unique trace file naming? Set to yes, no, or a numerical ID.
- no
- VT_MAX_FLUSHES
- Maximum number of buffer flushes.
- 1
- VT_MAX_THREADS
- Maximum number of threads per process that VampirTrace reserves resources for.
- 65536
- VT_PFORM_GDIR
- Name of global directory to store final trace file in.
- ./
- VT_PFORM_LDIR
- Name of node-local directory which can be used to store temporary trace
- files.
- VT_UNIFY
- Unify local trace files afterwards?
- yes
- VT_VERBOSE
- Level of VampirTrace related information messages: Quiet (0), Critical
- (1), Information (2)
-
- VT_CPUIDTRACE
- Enable tracing of CPU ID?
- no
- VT_ETIMESYNC
- Enable enhanced timer synchronization? ⇒ Section
- [#timer_synchronization [*]]
- VT_ETIMESYNC_INTV
- Interval between two successive synchronization phases in s.
- 120
- VT_IOLIB_PATHNAME
- Provides an alternative library to use for LIBC I/O calls.
-
- VT_IOTRACE
- Enable tracing of application I/O calls?
- no
- VT_LIBCTRACE
- Enable tracing of fork/system/exec calls?
- yes
- VT_MEMTRACE
- Enable memory allocation counter?
- no
- VT_MODE
- Colon-separated list of VampirTrace modes: Tracing (TRACE), Profiling
- (STAT).
- VT_MPICHECK
- Enable MPI correctness checking via UniMCI?
- no
- VT_MPICHECK_ERREXIT
- Force trace write and application exit if an MPI usage error is
- detected?
- VT_MPITRACE
- Enable tracing of MPI events?
- yes
- VT_PTHREAD_REUSE
- Reuse IDs of terminated Pthreads?
- yes
- VT_STAT_INV
- Length of interval for writing the next profiling record
- 0
- VT_STAT_PROPS
- Colon-separated list of event types that will be recorded in profiling
mode: Functions (FUNC), Messages (MSG), Collective Ops. (COLLOP) or all
of them (ALL)
- VT_SYNC_FLUSH
- Enable synchronized buffer flush?
- no
- VT_SYNC_FLUSH_LEVEL
- Minimum buffer fill level for synchronized buffer flush in percent.
- 80
-
- VT_METRICS
- Specify counter metrics to be recorded with trace events as a
- colon-separated list of names
- VT_RUSAGE
- Colon-separated list of resource usage counters which will be recorded.
-
- VT_RUSAGE_INTV
- Sample interval for recording resource usage counters in ms.
- 100
-
- VT_DYN_BLACKLIST
- Name of blacklist file for Dyninst instrumentation.
-
- VT_DYN_SHLIBS
- Colon-separated list of shared libraries for Dyninst instrumentation.
-
- VT_FILTER_SPEC
- Name of function/region filter file.
- VT_GROUPS_SPEC
- Name of function grouping file.
-
- VT_JAVA_FILTER_SPEC
- Name of Java specific filter file.
-
- VT_GROUP_CLASSES
- Create a group for each Java class automatically?
- yes
- VT_MAX_STACK_DEPTH
- Maximum number of stack level to be traced. (0 = unlimited)
- 0
-
- VT_GNU_DEMANGLE
- Decode (demangle) low-level symbol names into user-level names?
- no
- VT_GNU_GETSRC
- Retrieve the source code line of functions instrumented automatically
- with the GNU interface?
- VT_GNU_NMFILE
- Name of file with symbol list information.
-
When you use these environment variables, make sure that they have the
same value for all processes of your application on all nodes of your
cluster. Some cluster environments do not automatically transfer your
environment when executing parts of your job on remote nodes of the
cluster, and you may need to explicitly set and export them in batch job
submission scripts.
Influencing Trace Buffer Size
The default values of the environment variables VT_BUFFER_SIZE and
VT_MAX_FLUSHES limit the internal buffer of VampirTrace to 32 MB per
process, and the number of times that the buffer is flushed to 1,
respectively. Events that are to be recorded after the limit has been
reached are no longer written into the trace file. The environment
variables apply to every process of a parallel application, meaning that
applications with n processes will typically create trace files n times
the size of a serial application.
To remove the limit and get a complete trace of an application, set
VT_MAX_FLUSHES to 0. This causes VampirTrace to always write the
buffer to disk when it is full. To change the size of the buffer, use
the environment variable VT_BUFFER_SIZE. The optimal value for this
variable depends on the application which is to be traced. Setting a
small value will increase the memory available to the application, but
will trigger frequent buffer flushes by VampirTrace. These buffer
flushes can significantly change the behavior of the application. On the
other hand, setting a large value, like 2G, will minimize buffer flushes
by VampirTrace, but decrease the memory available to the application. If
not enough memory is available to hold the VampirTrace buffer and the
application data, parts of the application may be swapped to disk,
leading to a significant change in the behavior of the application.
Note that you can decrease the size of trace files significantly by
using the runtime function filtering.
Profiling an Application
Profiling an application collects aggregated information about certain
events during a program run, whereas tracing records information about
individual events. Profiling can therefore be used to get a summary of
the program activity and to detect events that are called very often.
The profiling information can also be used to generate filter rules to
reduce the trace file size.
To profile an application, set the variable VT_MODE to STAT. Setting
VT_MODE to STAT:TRACE tells VampirTrace to perform tracing and
profiling at the same time. By setting the variable VT STAT PROPS, the
user can influence whether functions, messages, and/or collective
operations shall be profiled.
Unification of Local Traces
After a run of an instrumented application, the traces of the single
processes need to be unified in terms of timestamps and event IDs. In
most cases, this happens automatically. If the environment variable
VT_UNIFY is set to no, and in the case of certain other circumstances,
it will be necessary to perform unification of local traces manually. To
do this, use the following command:
If VampirTrace was built with support for OpenMP and/or MPI, it is
possible to speedup the unification of local traces significantly. To
distribute the unificationon multible processes, the MPI parallel
version vtunify-mpi can be used as follows:
mpirun -np <nranks> vtunify-mpi <nproc> <prefix>
Furthermore, both tools vtunify and vtunify-mpi are capable of opening
additional OpenMP threads for unification. The number of threads can be
specified by the OMP_NUM_THREADS environment variable.
Synchronized Buffer Flush
When tracing an application, VampirTrace temporarily stores the recorded
events in a trace buffer. Typically, if a buffer of a process or thread
has reached its maximum fill level, the buffer has to be flushed and
other processes or threads may have to wait for this process or thread.
This will result in an asynchronous runtime behavior.
To avoid this problem, VampirTrace provides a buffer flush in a
synchronized manner. This means that if one buffer has reached its
minimum buffer fill level VT_SYNC_FLUSH_LEVEL, all buffers will be
flushed. This buffer flush is only available at appropriate points in
the program flow. Currently, VampirTrace makes use of all MPI collective
functions associated with MPI_COMM_WORLD. Use the environment variable
VT_SYNC_FLUSH to enable synchronized buffer flush.
Enhanced Timer Synchronization
Especially on cluster environments, where each process has its own local
timer, tracing relies on precisely synchronized timers. Therefore,
VampirTrace provides several mechanisms for timer synchronization. The
default synchronization scheme is a linear synchronization at the very
beginning and very end of a trace run with a master-slave communication
pattern.
However, this way of synchronization can become too imprecise for long
trace runs. Therefore, we recommend the usage of the enhanced timer
synchronization scheme of VampirTrace. This scheme inserts additional
synchronization phases at appropriate points in the program flow.
Currently, VampirTrace makes use of all MPI collective functions
associated with MPI_COMM_WORLD.
To enable this synchronization scheme, a LAPACK library with C wrapper
support has to be provided for VampirTrace, and the environment variable
VT_ETIMESYNC has to be set before the tracing. The length of the
interval between two successive synchronization phases can be adjusted
with VT_ETIMESYNC_INTV. The following LAPACK libraries provide a
C-LAPACK API that can be used by VampirTrace for the enhanced timer
synchronization:
- CLAPACK
- AMD ACML
- IBM ESSL
- Intel MKL
- SUN Performance Library
Note: Systems equipped with a global timer do not need timer
synchronization.
Note: It is recommended to combine enhanced timer synchronization
and synchronized buffer flush.
Note: Be aware that the asynchronous behavior of the application
will be disturbed since VampirTrace makes use of asynchronous MPI
collective functions for timer synchronization and synchronized buffer
flush. Only make use of these approaches if your application does not
rely on an asynchronous behavior! Otherwise, keep this fact in mind
during the process of performance analysis.
Recording Additional Events and Counters
Hardware Performance Counters
If VampirTrace has been built with hardware counter support, it is
capable of recording hardware counter information as part of the event
records. To request the measurement of certain counters, the user is
required to set the environment variable VT_METRICS. The variable
should contain a colon-separated list of counter names or a predefined
platform-specific group.
The user can leave the environment variable unset to indicate that no
counters are requested. If any of the requested counters are not
recognized or the full list of counters cannot be recorded due to
hardware resource limits, program execution will be aborted with an
error message.
PAPI Hardware Performance Counters
If the PAPI library is used to access hardware performance counters,
metric names can be any PAPI preset names or PAPI native counter names.
For example, set
VT\_METRICS=PAPI\_FP\_OPS:PAPI\_L2\_TCM
to record the number of floating point instructions and level 2 cache
misses.
Resource Usage Counters
The Unix system call getrusage provides information about consumed
resources and operating system events of processes such as user/system
time, received signals, and context switches.
If VampirTrace has been built with resource usage support, it is able to
record this information as performance counters to the trace. You can
enable tracing of specific resource counters by setting the environment
variable VT_RUSAGE to a colon-separated list of counter names. For
example, set
VT\_RUSAGE=ru\_stime:ru\_majflt
to record the system time consumed by each process and the number of
page faults. Alternatively, one can set this variable to the value all
to enable recording of all 16 resource usage counters. Note that not all
counters are supported by all Unix operating systems. Linux 2.6 kernels,
for example, support only resource information for six of them.
The resource usage counters are not recorded at every event. They are
only read if 100 ms have passed since the last sampling. The interval
can be changed by setting VT_RUSAGE_INTV to the number of desired
milliseconds. Setting VT_RUSAGE_INTV to zero leads to sampling
resource usage counters at every event, which may introduce a large
runtime overhead. Note that in most cases the operating system does not
update the resource usage information at the same high frequency as the
hardware performance counters. Setting VT_RUSAGE_INTV to a value less
than 10 ms does not usually improve the granularity.
Be aware that, when using the resource usage counters for multi-threaded
programs, the information displayed is valid for the whole process and
not for each single thread.
Memory Allocation Counter
The GNU LIBC implementation provides a special hook mechanism that
allows intercepting all calls to memory allocation and free functions
(e.g. malloc, realloc, free). This is independent from compilation or
source code access, but relies on the underlying system library.
If VampirTrace has been built with memory-tracing support, VampirTrace
is capable of recording memory allocation information as part of the
event records. To request the measurement of the application’s allocated
memory, the user must set the environment variable VT_MEMTRACE to yes.
Note: This approach to get memory allocation information requires
changing internal function pointers in a non-thread-safe way, so
VampirTrace currently does not support memory tracing for threadable
programs, e.g., programs parallelized with OpenMP or Pthreads!
Pthread API Calls
When tracing applications with Pthreads, only user events and functions
are recorded which are automatically or manually instrumented. Pthread
API functions will not be traced by default. To enable tracing of all
C-Pthread API functions, include the header vt user.h and compile the
instrumented sources with -DVTRACE PTHREAD.
C/C++
#include "vt\_user.h"
vtcc **-DVTRACE\_PTHREAD** hello.c -o hello
I/O Calls
Calls to functions which reside in external libraries can be intercepted
by implementing identical functions and linking them before the external
library. Such “wrapper functions” can record the parameters and return
values of the library functions.
If VampirTrace has been built with I/O tracing support, it uses this
technique for recording calls to I/O functions of the standard C
library, which are executed by the application. The following functions
are intercepted by VampirTrace:
The gathered information will be saved as I/O event records in the trace
file. This feature has to be activated for each tracing run by setting
the environment variable VT_IOTRACE to yes.
This works for both dynamically and statically linked executables. Note
that when linking statically, a warning like the following may be
issued: Using “dlopen” in statically linked applications requires at
runtime the shared libraries from the glibc version used for linking.
This is ok as long as the mentioned libraries are available for running
the application.
If you’d like to experiment with some other I/O library, set the
environment variable VT_IOLIB_PATHNAME to the alternative one. Beware
that this library must provide all I/O functions mentioned above;
otherwise VampirTrace will abort.
fork/system/exec Calls
If VampirTrace has been built with LIBC trace support, it is capable of
tracing programs which call functions from the LIBC exec family (execl,
execlp, execle, execv, execvp, execve), system, and fork. VampirTrace
records the call of the LIBC function to the trace. This feature works
for sequential (i.e., no MPI or threaded parallelization) programs only.
It works for both dynamically and statically linked executables. Note
that when linking statically, a warning like the following may be
issued: Using “dlopen” in statically linked applications requires at
runtime the shared libraries from the glibc version used for linking.
This is ok as long as the mentioned libraries are available for running
the application.
When VampirTrace detects a call of an exec function, the current trace
file is closed before executing the new program. If the executed program
is also instrumented with VampirTrace, it will create a different trace
file. Note that VampirTrace aborts if the exec function returns
unsuccessfully. Calling fork in an instrumented program creates an
additional process in the same trace file.
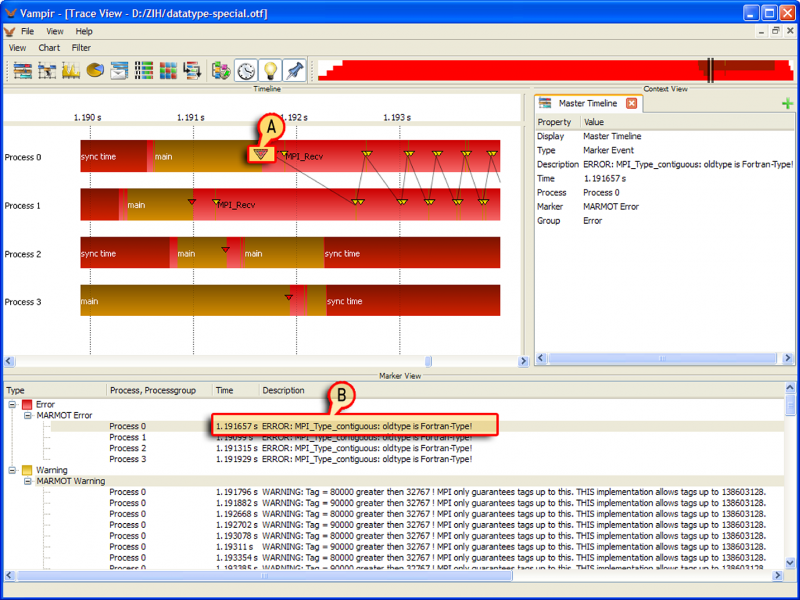
MPI Correctness Checking Using UniMCI
VampirTrace supports the recording of MPI correctness events, e.g.,
usage of invalid MPI requests. This is implemented by using the
Universal MPI Correctness Interface (UniMCI), which provides an
interface between tools like VampirTrace and existing runtime MPI
correctness checking tools. Correctness events are stored as markers in
the trace file and are visualized by Vampir. If VampirTrace is built
with UniMCI support, the user only has to enable MPI correctness
checking. This is done by merely setting the environment variable
VT_MPICHECK to yes. Further, if your application crashes due to an MPI
error you should set VT_MPICHECK_ERREXIT to yes. This environmental
variable forces VampirTrace to write its trace to disk and exit
afterwards. As a result, the trace with the detected error is stored
before the application might crash.
To install VampirTrace with correctness checking support, it is
necessary to have UniMCI installed on your system. UniMCI in turn
requires you to have a supported MPI correctness checking tool installed
(currently only the tool Marmot is known to have UniMCI support). So,
all in all, you should use the following order to install with
correctness checking support:
- Marmot
http://www.hlrs.de/organization/av/amt/research/marmot
- UniMCI
http://www.tu-dresden.de/zih/unimci
- VampirTrace
http://www.tu-dresden.de/zih/vampirtrace
Information on how to install Marmot and UniMCI is given in their
respective manuals. VampirTrace will automatically detect an UniMCI
installation if the unimci-config tool is in path.
User-defined Counters
In addition to the manual instrumentation, the VampirTrace API provides
instrumentation calls which allow recording of program variable values
(e.g., iteration counts, calculation results, ...) or any other
numerical quantity. A user-defined counter is identified by its name,
the counter group it belongs to, the type of its value (integer or
floating-point) and the unit that the value is quoted (e.g.
“GFlop/sec”). The VT_COUNT_GROUP_DEF and VT_COUNT_DEF
instrumentation calls can be used to define counter groups and counters:
Fortran
#include "vt\_user.inc"
integer :: id, gid
VT\_COUNT\_GROUP\_DEF(’name’, gid)
VT\_COUNT\_DEF(’name’, ’unit’, type, gid, id)
C/C++
#include "vt\_user.h"
unsigned int id, gid;
gid = VT\_COUNT\_GROUP\_DEF("name");
id = VT\_COUNT\_DEF("name", "unit", type, gid);
The definition of a counter group is optional. If no special counter
group is desired, the default group “User” can be used. In this case,
set the parameter gid of VT_COUNT_DEF() to VT_COUNT_DEFGROUP. The
third parameter type of VT_COUNT_DEF specifies the data type of the
counter value. To record a value for any of the defined counters, the
corresponding instrumentation call VT_COUNT * VAL must be invoked.
| Fortran: |
|
|
| Type |
Count call |
Data Type |
| VT_COUNT_TYPE_INTEGER |
VT_COUNT_INTEGER_VAL |
integer (4 byte) |
| VT_COUNT_TYPE_INTEGER8 |
VT_COUNT_INTEGER8_VAL |
integer (8 byte) |
| VT_COUNT_TYPE_REAL |
VT_COUNT_REAL_VAL |
real |
| VT_COUNT_TYPE_DOUBLE |
VT_COUNT_DOUBLE_VAL |
double precision |
The following example records the loop index i:
Fortran
#include “vt_user.inc”
program main
integer :: i, cid, cgid
VT_COUNT_GROUP_DEF(’loopindex’, cgid)
VT_COUNT_DEF(’i’, ’#’, VT_COUNT_TYPE_INTEGER, cgid, cid)
do i=1,100
VT_COUNT_INTEGER_VAL(cid, i)
end do
end program main
C/C++
#include “vt_user.h”
int main() {
unsigned int i, cid, cgid;
cgid = VT_COUNT_GROUP_DEF(’loopindex’);
cid = VT_COUNT_DEF(“i”, “#”, VT_COUNT_TYPE_UNSIGNED, cgid);
for( i = 1; i <= 100; i++ ) {
VT_COUNT_UNSIGNED_VAL(cid, i);
}
return 0;
}
For all three languages, the instrumented sources have to be compiled
with -DVTRACE. Otherwise, the VT * calls are ignored. Optionally, if
the sources contain further VampirTrace API calls and only the calls for
user-defined counters will be disabled, then the sources have to be
compiled with -DVTRACE_NO_COUNT in addition to -DVTRACE .
User-Defined Markers
In addition to the manual instrumentation, the VampirTrace API provides
instrumentation calls which allow recording of special user information,
which can be used to better identify parts of interest. A user-defined
marker is identified by its name and type.
Fortran
#include "vt\_user.inc"
integer?:: mid
VT\_MARKER\_DEF(’name’, type, mid)
VT\_MARKER(mid, ’text’)
C/C++
#include "vt\_user.h"
unsigned int mid;
mid = VT\_MARKER\_DEF("name",type);
VT\_MARKER(mid, "text");
Types for Fortran/C/C++
?
VT_MARKER_TYPE_ERROR
VT_MARKER_TYPE_WARNING
VT_MARKER_TYPE_HINT
For all three languages, the instrumented sources have to be compiled
with -DVTRACE. Otherwise, the VT * calls are ignored. Optionally, if
the sources contain further VampirTrace API calls and only the calls for
user-defined markers will be disabled, then the sources have to be
compiled with -DVTRACE_NO_MARKER in addition to -DVTRACE .
Filtering and Grouping
By default, all calls of instrumented functions will be traced;
consequently, the resulting trace files can easily become very large. In
order to decrease the size of a trace, VampirTrace allows the
specification of filter directives before running an instrumented
application. The user can decide on how often an instrumented
function/region should be recorded to a trace file. To use a filter, the
environment variable VT_FILTER_SPEC needs to be defined. It should
contain the path and name of a file with filter directives. Following is
an example of a file containing filter directives:
#VampirTrace region filter specification
#
#call limit definitions and region assignments
#
#syntax: <regions> – <limit>
#
#regions semicolon-separated list of regions
# (can be wildcards)
#limit assigned call limit
# 0 = region(s) denied
# -1 = unlimited
#
add;sub;mul;div – 1000
* – 3000000
These region filter directives allow the functions add, sub, mul and div
to be recorded at most 1000 times. The remaining functions * will be
recorded at most 3,000,000 times.
Besides creating filter files manually, you can also use the vtfilter
tool to generate them automatically. This tool reads a provided trace
and decides whether a function should be filtered or not, based on the
evaluation of certain parameters.
Rank Specific Filtering
An experimental extension allows rank specific filtering. Use @ clauses
to restrict all following filters to the given ranks. The rank selection
must be given as a list of <from> - <to> pairs or single values.
@ 4 - 10, 20 - 29, 34
foo;bar – 2000
* – 0
The example defines two limits for the ranks 4 - 10, 20 - 29, and 34.
Attention: The rank specific rules are activated later than usual at
MPI Init, because the ranks are not available earlier. The special MPI
routines MPI Init, MPI Init thread, and MPI Initialized cannot be
filtered in this way.
Function Grouping
VampirTrace allows assigning functions/regions to a group. Groups can,
for instance, be highlighted by different colors in Vampir displays. The
following standard groups are created by VampirTrace:
Group name
Contained functions/regions
MPI
MPI functions
OMP
OpenMP API function calls
OMP_SYNC
OpenMP barriers
OMP_PREG
OpenMP parallel regions
Pthreads
Pthread API function calls
MEM
Memory allocation functions (⇒ Section [#mem_alloc_counter [*]])
I/O
I/O functions (⇒ Section [#io_calls [*]])
LIBC
LIBC fork/system/exec functions (⇒ Section [#execfork [*]])
Application
remaining instrumented functions and source code regions
Additionally, you can create your own groups, if, for example, you wish
to better distinguish different phases of an application. To use
function/region grouping, set the environment variable VT_GROUPS_SPEC
to the path of a file which contains the group assignments. Below is an
example of how to use group assignments:
# VampirTrace region groups specification
#
# group definitions and region assignments
#
# syntax: <group>=<regions>
#
# group group name
# regions semicolon-separated list of regions
# (can be wildcards)
#
CALC=add;sub;mul;div
USER=app_*
These group assignments associate the functions add, sub, mul and div
with group “CALC”, and all functions with the prefix app are associated
with group “USER”.