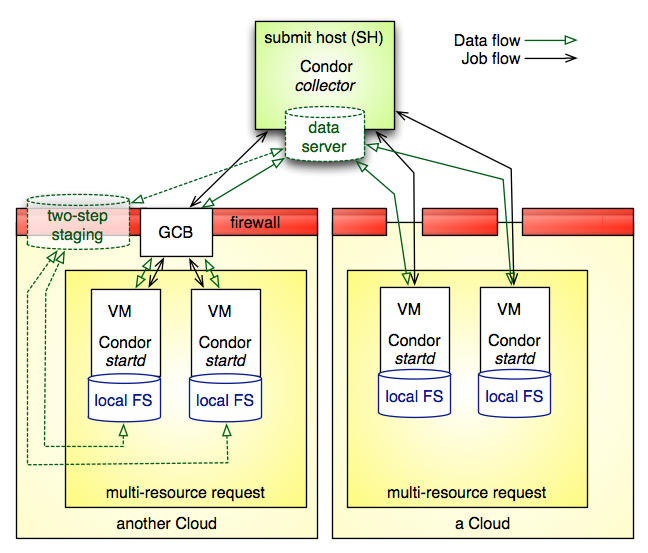
-
Site
- 1. INTRODUCTION
- 2. ACCOUNTS AND PROJECTS
- 2.1. Project and Account Management
- 2.2. Using SSH Keys
- 3. STATUS
- 4. HPC SERVICES
- 4.1. Hardware
- 4.2. HPC Services
- 4.3. ScaleMP vSMP
- 4.4. Genesis II
- 4.5. Unicore
- 4.5.1. UNICORE 6 on FutureGrid User Manual
- 4.5.2. Introduction
- 4.5.3. What is UNICORE?
- 4.5.4. Connecting to the UNICORE BES Endpoints From Other Grid Middleware Clients
- 4.5.5. Connecting to the UNICORE BES Endpoints Using a UNICORE Commandline Client
- 4.5.5.1. Installing the UNICORE 6 Commandline Client (UCC)
- 4.5.5.2. Configuring Client to Connect to FutureGrid U6 Endpoints
- 4.5.5.3. Setting Up Security in UNICORE
- 4.5.5.4. Setting Up a Keystore
- 4.5.5.4.1. Creating a Truststore
- 4.5.5.4.2. Acquiring the Registry Address
- 4.5.5.4.3. Connecting to Endpoints w/o Registries
- 4.5.5.4.4. Preferences File Modifications
- 4.5.5.4.5. Example Preferences File
- 4.5.5.4.6. Locating the Preferences File
- 4.5.5.4.7. Validate Client Setup
- 4.5.5.4.8. Configuration Conclusion
- 4.5.5.5. Submitting Jobs to FutureGrid U6 Endpoints
- 4.5.5.6. References
- 4.5.5.7. Questions/Comments
- 4.5.6. Running Jobs on UNICORE Sites
- 4.5.7. Deploying a New UNICORE 6 Grid
- 5. IAAS/CLOUD SERVICES
- 5.1. IaaS
- 5.2. OpenStack Havana
- 5.2.1. Login
- 5.2.2. Setup OpenStack Environment
- 5.2.3. Creating the novarc file
- 5.2.4. List flavors
- 5.2.5. List images
- 5.2.6. Key management
- 5.2.7. Managing security groups
- 5.2.8. Booting an image
- 5.2.9. List running images
- 5.2.10. Use block storage
- 5.2.11. Set up external access to your instance
- 5.2.12. Make a snapshot of an instance
- 5.2.13. Automate some initial configuration
- 5.2.14. Get the latest version of Ubuntu Cloud Image and upload it to the OpenStack
- 5.2.15. Delete your instance
- 5.2.16. How to change your password
- 5.2.17. Things to do when you need Euca2ools or EC2 interfaces
- 5.2.18. Horizon GUI
- 5.2.19. Getting rc files via Horizon
- 5.3. OpenStack Grizzly
- 5.3.1. Login
- 5.3.2. Creating the novarc file
- 5.3.3. Activate OpenStack tools
- 5.3.4. List flavors
- 5.3.5. List images
- 5.3.6. Standard Images
- 5.3.7. Key management
- 5.3.8. Managing security groups
- 5.3.9. Booting an image
- 5.3.10. List running images
- 5.3.11. Use block storage
- 5.3.12. Set up external access to your instance
- 5.3.13. Make a snapshot of an instance
- 5.3.14. Automate some initial configuration
- 5.3.15. Get the latest version of Ubuntu Cloud Image and upload it to the OpenStack
- 5.3.16. Delete your instance
- 5.3.17. How to change your password
- 5.3.18. Horizon GUI
- 5.4. Openstack Horizon
- 5.5. Converting Virtualbox images to OpenStack
- 5.5.1. Prerequisites
- 5.5.2. Convert your virtual box image to raw format
- 5.5.3. Convert the image to qcow2 format (optional)
- 5.5.4. Test your image
- 5.5.5. Transfer your Image to India
- 5.5.6. Log into India
- 5.5.7. Upload your image to OpenStack
- 5.5.8. Checking Status Image
- 5.5.9. Test Image in OpenStack
- 5.5.10. Troubleshooting
- 5.5.11. Notes:
- 5.6. Nimbus
- 5.7. Eucalyptus
- 6. PAAS/CLOUD SERVICES
- 6.1. Using Hadoop in FutureGrid
- 6.1.1. Running Hadoop as a Batch Job using MyHadoop
- 6.1.1.1. myHadoop on FutureGrid
- 6.1.1.1.1. Login into a machine tha has myHadoop installed
- 6.1.1.1.2. Load the needed modules
- 6.1.1.1.3. Run the Example
- 6.1.1.1.4. Details of the Script
- 6.1.1.1.5. Submission of the Hadoop job
- 6.1.1.1.6. Persistent Mode
- 6.1.1.1.7. Customizing Hadoop Settings
- 6.1.1.1.8. Using a Different Installation of Hadoop
- 6.1.1.1.9. References
- 6.1.1.1. myHadoop on FutureGrid
- 6.1.1. Running Hadoop as a Batch Job using MyHadoop
- 6.2. Using Twister in FutureGrid
- 6.1. Using Hadoop in FutureGrid
- 7. EXPERIMENT MANAGEMENT SERVICES
- 7.1. Interactive Experiment Management
- 7.2. Precip
- 7.3. Pegasus
- 7.4. RAIN
- 7.4.1. Generate and Register an OS Image on FutureGrid using the FG Shell
- 7.4.2. FutureGrid Standalone Image Repository
- 7.4.3. Manual Image Customization
- 7.4.3.1. Logging into India
- 7.4.3.2. Requesting access
- 7.4.3.3. Obtaining the image
- 7.4.3.4. Customizing the image
- 7.4.3.5. Transfer the image back to India
- 7.4.3.6. Log into India
- 7.4.3.7. Upload the image to the repository
- 7.4.3.8. Register your image in different infrastructures
- 7.4.3.9. Using your Registered Image
- 7.4.4. RAIN Manual Pages
- 8. PERFORMANCE TOOLS
- 9. TUTORIALS
- 2. Tutorials
- 2.1. Tutorial Topic 0: Accessing FutureGrid Resources
- 2.2. Tutorial Topic 1: Cloud Provisioning Platforms
- 2.3. Tutorial Topic 2: Cloud Run-time Map/Reduce Platforms
- 2.4. Tutorial Topic 3: Grid Appliances for Training, Education, and Outreach
- 2.5. Tutorial Topic 4: High Performance Computing
- 2.6. Tutorial Topic 5: Experiment Management
- 2.7. Tutorial Topic 6: Image Management and Rain
- 2.8. Tutorial Topic 7: Storage
- 2.9. Other Tutorials and Educational Materials
- 2. Tutorials
- 10. APPENDIX. SCREENCASTS
- 11. APPENDIX. MAINTAINING THIS MANUAL
- 11.1. Git
- 11.2. Contributing to the Manual
- 11.3. Setting Up the Expert Developers Manual Editing Environment
- 11.3.1. Python
- 11.3.2. Virtualenv
- 11.3.3. Create a github local directory with the manual
- 11.3.4. Install the Requirements
- 11.3.5. All-in-one setup script
- 11.3.6. Watchdog
- 11.3.7. Transfering a page from the portal to RST
- 11.3.8. Creating the pages locally
- 11.3.9. Publishing the pages
- 11.3.10. Jira
- 11.3.11. Portal link
- 11.3.12. Screencast recording tips
- 12. APPENDIX. MPI RING PROGRAM
- 13. APPENDIX. OTHER SECTIONS THAT HAVE NOT YET BEEN REVIEWED OR ARE INTEGRATED IN THE MANUAL
- 3. Delta GPU User Manual
- 13.2. IPOP (IP-over-P2P)
- 13.3. IPOP2 (IP-over-P2P)
- 13.3.1. Prerequisites:
- 13.3.2. Step 1: Bringing up Alice and Bob VMs
- 13.3.3. Step 2: Disconnecting Alice and Bob VMs from the PlanetLab P2P overlay
- 13.3.4. Step 3: Deploy Pam, a P2P Bootstrapping VM
- 13.3.5. Step 4: Configure Pam to run P2P Bootstrapping Overlay
- 13.3.6. Step 5: Configure Alice and Bob to use Pam as P2P overlay
- 13.3.7. Step 6: Send messages between Alice and Bob
- 13.3.8. 7.1) Inspecting the P2P network
- 13.3.9. 7.2) Adding fault tolerance by deploying multiple bootstrap nodes
- 13.4. GA1
- 13.5. GA9
- 13.6. HPSS
- 13.7. SSH the wrong way ( DO NOT USE THIS TUTORIAL)
- 1. INTRODUCTION
- 2. ACCOUNTS AND PROJECTS
- 2.1. Project and Account Management
- 2.2. Using SSH Keys
- 3. STATUS
- 4. HPC SERVICES
- 4.1. Hardware
- 4.2. HPC Services
- 4.3. ScaleMP vSMP
- 4.4. Genesis II
- 4.5. Unicore
- 4.5.1. UNICORE 6 on FutureGrid User Manual
- 4.5.2. Introduction
- 4.5.3. What is UNICORE?
- 4.5.4. Connecting to the UNICORE BES Endpoints From Other Grid Middleware Clients
- 4.5.5. Connecting to the UNICORE BES Endpoints Using a UNICORE Commandline Client
- 4.5.5.1. Installing the UNICORE 6 Commandline Client (UCC)
- 4.5.5.2. Configuring Client to Connect to FutureGrid U6 Endpoints
- 4.5.5.3. Setting Up Security in UNICORE
- 4.5.5.4. Setting Up a Keystore
- 4.5.5.4.1. Creating a Truststore
- 4.5.5.4.2. Acquiring the Registry Address
- 4.5.5.4.3. Connecting to Endpoints w/o Registries
- 4.5.5.4.4. Preferences File Modifications
- 4.5.5.4.5. Example Preferences File
- 4.5.5.4.6. Locating the Preferences File
- 4.5.5.4.7. Validate Client Setup
- 4.5.5.4.8. Configuration Conclusion
- 4.5.5.5. Submitting Jobs to FutureGrid U6 Endpoints
- 4.5.5.6. References
- 4.5.5.7. Questions/Comments
- 4.5.6. Running Jobs on UNICORE Sites
- 4.5.7. Deploying a New UNICORE 6 Grid
- 5. IAAS/CLOUD SERVICES
- 5.1. IaaS
- 5.2. OpenStack Havana
- 5.2.1. Login
- 5.2.2. Setup OpenStack Environment
- 5.2.3. Creating the novarc file
- 5.2.4. List flavors
- 5.2.5. List images
- 5.2.6. Key management
- 5.2.7. Managing security groups
- 5.2.8. Booting an image
- 5.2.9. List running images
- 5.2.10. Use block storage
- 5.2.11. Set up external access to your instance
- 5.2.12. Make a snapshot of an instance
- 5.2.13. Automate some initial configuration
- 5.2.14. Get the latest version of Ubuntu Cloud Image and upload it to the OpenStack
- 5.2.15. Delete your instance
- 5.2.16. How to change your password
- 5.2.17. Things to do when you need Euca2ools or EC2 interfaces
- 5.2.18. Horizon GUI
- 5.2.19. Getting rc files via Horizon
- 5.3. OpenStack Grizzly
- 5.3.1. Login
- 5.3.2. Creating the novarc file
- 5.3.3. Activate OpenStack tools
- 5.3.4. List flavors
- 5.3.5. List images
- 5.3.6. Standard Images
- 5.3.7. Key management
- 5.3.8. Managing security groups
- 5.3.9. Booting an image
- 5.3.10. List running images
- 5.3.11. Use block storage
- 5.3.12. Set up external access to your instance
- 5.3.13. Make a snapshot of an instance
- 5.3.14. Automate some initial configuration
- 5.3.15. Get the latest version of Ubuntu Cloud Image and upload it to the OpenStack
- 5.3.16. Delete your instance
- 5.3.17. How to change your password
- 5.3.18. Horizon GUI
- 5.4. Openstack Horizon
- 5.5. Converting Virtualbox images to OpenStack
- 5.5.1. Prerequisites
- 5.5.2. Convert your virtual box image to raw format
- 5.5.3. Convert the image to qcow2 format (optional)
- 5.5.4. Test your image
- 5.5.5. Transfer your Image to India
- 5.5.6. Log into India
- 5.5.7. Upload your image to OpenStack
- 5.5.8. Checking Status Image
- 5.5.9. Test Image in OpenStack
- 5.5.10. Troubleshooting
- 5.5.11. Notes:
- 5.6. Nimbus
- 5.7. Eucalyptus
- 6. PAAS/CLOUD SERVICES
- 6.1. Using Hadoop in FutureGrid
- 6.1.1. Running Hadoop as a Batch Job using MyHadoop
- 6.1.1.1. myHadoop on FutureGrid
- 6.1.1.1.1. Login into a machine tha has myHadoop installed
- 6.1.1.1.2. Load the needed modules
- 6.1.1.1.3. Run the Example
- 6.1.1.1.4. Details of the Script
- 6.1.1.1.5. Submission of the Hadoop job
- 6.1.1.1.6. Persistent Mode
- 6.1.1.1.7. Customizing Hadoop Settings
- 6.1.1.1.8. Using a Different Installation of Hadoop
- 6.1.1.1.9. References
- 6.1.1.1. myHadoop on FutureGrid
- 6.1.1. Running Hadoop as a Batch Job using MyHadoop
- 6.2. Using Twister in FutureGrid
- 6.1. Using Hadoop in FutureGrid
- 7. EXPERIMENT MANAGEMENT SERVICES
- 7.1. Interactive Experiment Management
- 7.2. Precip
- 7.3. Pegasus
- 7.4. RAIN
- 7.4.1. Generate and Register an OS Image on FutureGrid using the FG Shell
- 7.4.2. FutureGrid Standalone Image Repository
- 7.4.3. Manual Image Customization
- 7.4.3.1. Logging into India
- 7.4.3.2. Requesting access
- 7.4.3.3. Obtaining the image
- 7.4.3.4. Customizing the image
- 7.4.3.5. Transfer the image back to India
- 7.4.3.6. Log into India
- 7.4.3.7. Upload the image to the repository
- 7.4.3.8. Register your image in different infrastructures
- 7.4.3.9. Using your Registered Image
- 7.4.4. RAIN Manual Pages
- 8. PERFORMANCE TOOLS
- 9. TUTORIALS
- 2. Tutorials
- 2.1. Tutorial Topic 0: Accessing FutureGrid Resources
- 2.2. Tutorial Topic 1: Cloud Provisioning Platforms
- 2.3. Tutorial Topic 2: Cloud Run-time Map/Reduce Platforms
- 2.4. Tutorial Topic 3: Grid Appliances for Training, Education, and Outreach
- 2.5. Tutorial Topic 4: High Performance Computing
- 2.6. Tutorial Topic 5: Experiment Management
- 2.7. Tutorial Topic 6: Image Management and Rain
- 2.8. Tutorial Topic 7: Storage
- 2.9. Other Tutorials and Educational Materials
- 2. Tutorials
- 10. APPENDIX. SCREENCASTS
- 11. APPENDIX. MAINTAINING THIS MANUAL
- 11.1. Git
- 11.2. Contributing to the Manual
- 11.3. Setting Up the Expert Developers Manual Editing Environment
- 11.3.1. Python
- 11.3.2. Virtualenv
- 11.3.3. Create a github local directory with the manual
- 11.3.4. Install the Requirements
- 11.3.5. All-in-one setup script
- 11.3.6. Watchdog
- 11.3.7. Transfering a page from the portal to RST
- 11.3.8. Creating the pages locally
- 11.3.9. Publishing the pages
- 11.3.10. Jira
- 11.3.11. Portal link
- 11.3.12. Screencast recording tips
- 12. APPENDIX. MPI RING PROGRAM
- 13. APPENDIX. OTHER SECTIONS THAT HAVE NOT YET BEEN REVIEWED OR ARE INTEGRATED IN THE MANUAL
- 3. Delta GPU User Manual
- 13.2. IPOP (IP-over-P2P)
- 13.3. IPOP2 (IP-over-P2P)
- 13.3.1. Prerequisites:
- 13.3.2. Step 1: Bringing up Alice and Bob VMs
- 13.3.3. Step 2: Disconnecting Alice and Bob VMs from the PlanetLab P2P overlay
- 13.3.4. Step 3: Deploy Pam, a P2P Bootstrapping VM
- 13.3.5. Step 4: Configure Pam to run P2P Bootstrapping Overlay
- 13.3.6. Step 5: Configure Alice and Bob to use Pam as P2P overlay
- 13.3.7. Step 6: Send messages between Alice and Bob
- 13.3.8. 7.1) Inspecting the P2P network
- 13.3.9. 7.2) Adding fault tolerance by deploying multiple bootstrap nodes
- 13.4. GA1
- 13.5. GA9
- 13.6. HPSS
- 13.7. SSH the wrong way ( DO NOT USE THIS TUTORIAL)
- Page
- « 7.2. Precip
- 7.4. RAIN »